正则表达式
正则在线测试网站:https://regexr-cn.com
正则练习平台:https://www.codejiaonang.com/#/course/regex_chapter1/0/0
[]字符集:匹配集合中的任何字符
-表示区间,例如:[a-z]表示小写字母a到z\转义特殊字符,[\]]表示匹配]^表示取非,[^]称作非集,匹配不在集合中的任何字符,例如我[^你]匹配我字后面没有你字(匹配两个字)
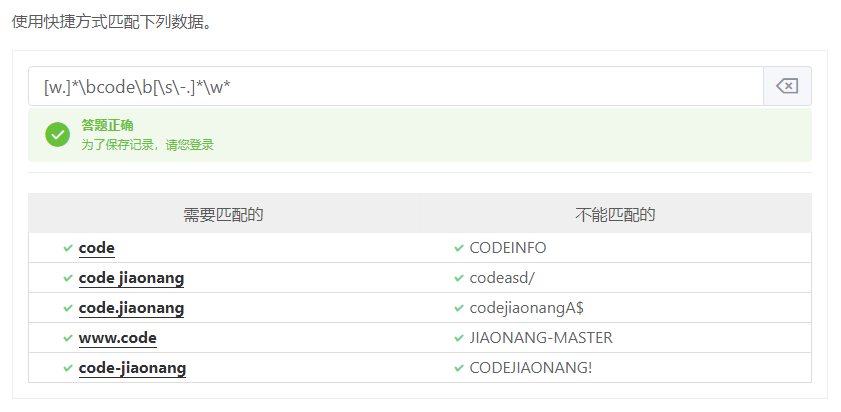
快捷方式
\d数字,匹配任意数字(0-9)
\w单词,匹配字母、数字、下划线
\s空白字符,匹配任何空白字符。(空格,制表符tab,换行符)
\b词边界,匹配一个单词边界,也就是指单词和空格见的位置,成对使用,例如\bawesome\b,匹配完整的单词,前后不能有其他字母,否则将匹配失败
快捷方式取非,将上述dwsb等字母,换成大写即可
开头和结尾
^开头,匹配字符串开头,或者当使用多行标志时,匹配一行的开头
$结尾,匹配字符串结尾,或者当使用多行标志时,匹配一行的结尾
例如^abcd会匹配abcdefg中的abcd,efg$会匹配abcdefg中的efg
任意字符
.,匹配任何字符(不包括换行)
量词
?,匹配在0和1之间个前面的标记,例如favou?r,匹配的时favour和favor
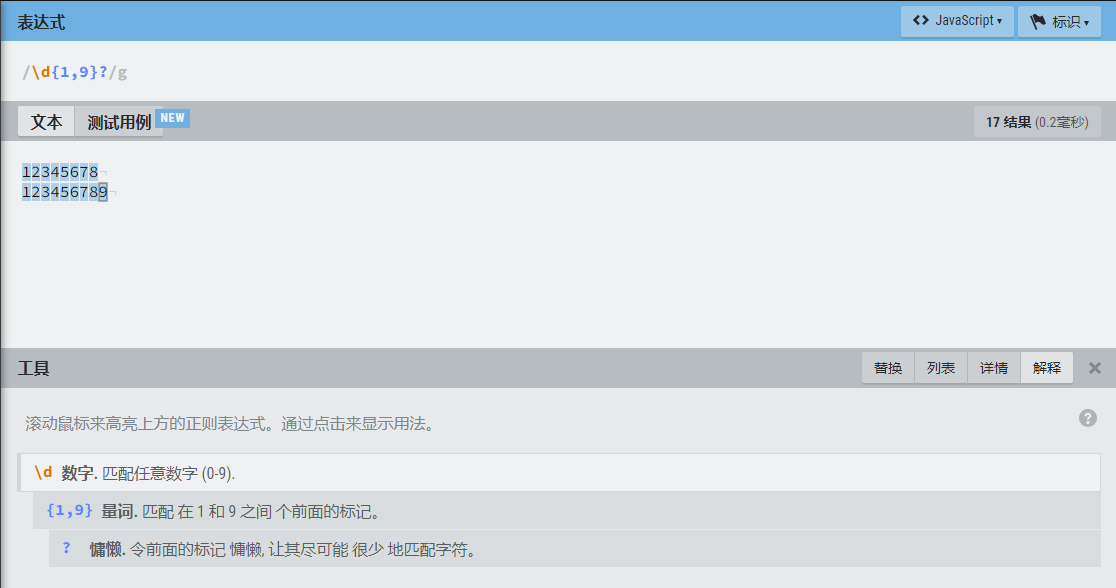
{n},匹配n个前面的标记,例如\d{10},匹配连续10个数字
{n,m}贪婪模式,匹配n到m个前面的标记,有连续的m个就会匹配m个
{n,m}?非贪婪模式,只会匹配到连续的n个就停止匹配,例如下图
*,匹配0个或更多个前面的标记,例如f.*,会匹配所有f开头的字符
+,匹配1个或更多个前面的标记,例如f.+,会匹配所有f开头的字符,但不匹配单独的f
分组提取
()捕获分组,把多个标记分在同一组并创建一个捕获分组,用来创建子串或引用
|或者条件
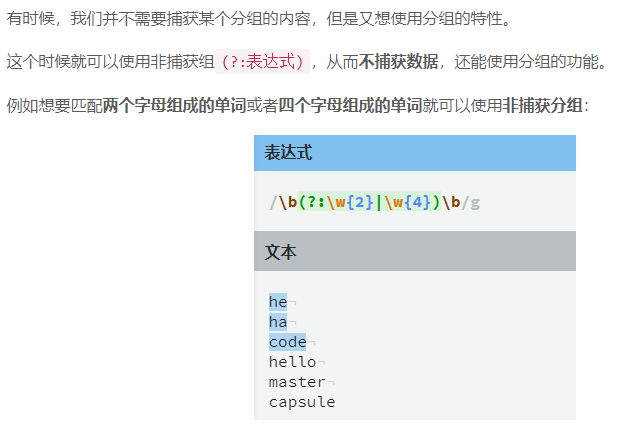
(?:表达式)非捕获分组,在不创建捕获分组的情况下,把数个标记组在一起
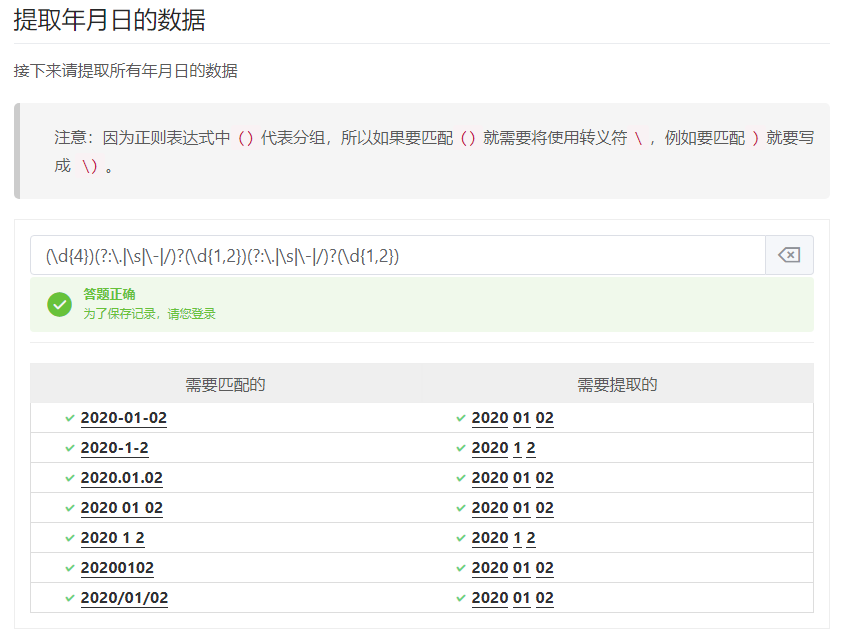
(表达式)\1分组的回溯引用,\1的效果是重新使用第1个分组去匹配,例如(\w)(\w)\2\1,匹配abba这种类型的字符,注:只有()有效,(?:)等无效
断言
可以理解为预搜索,可对字符串做限制要求
先行(表示从某个位置向右看)
(?=)正向先行断言,匹配主表达式后面的组而不将其包含在结果中(保证右边含有某字符)
可以翻译为:(?=表达式)右边存在
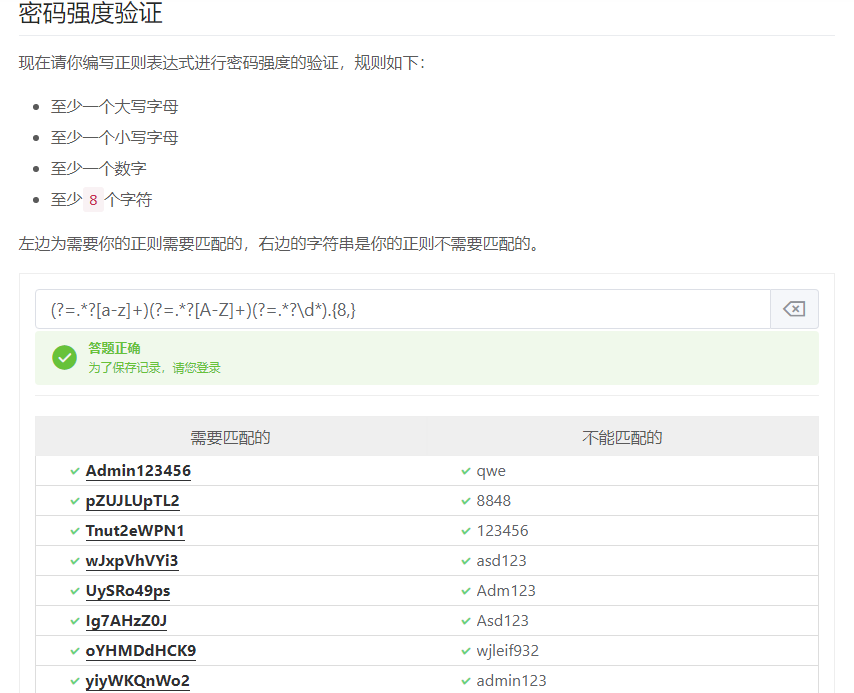
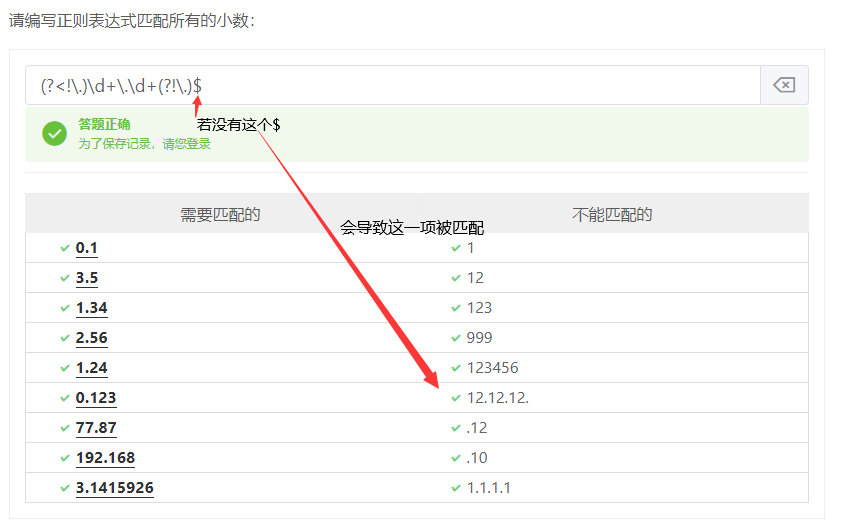
(?!)反向先行断言,指定著表达式后无法匹配的组,若匹配结果将被丢弃(保证右边不出现某字符)
可以翻译为:(?!表达式)右边不存在
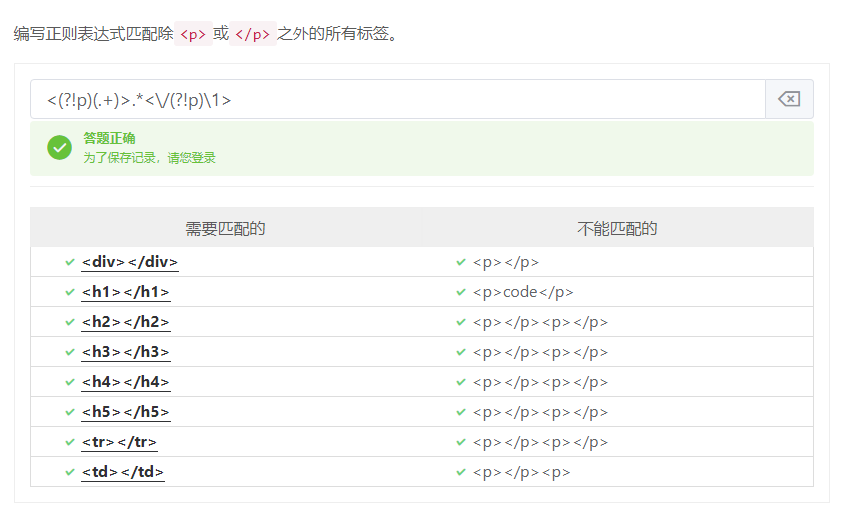
tips:正向是=,反向是!,也即正向是有,反向是没有
后行(表示从某个位置向左看)
(?<=)正向后行断言,匹配主表达式之前的组,而不将其包含在结果中
可以翻译为:(?<=表达式)左边存在
(?<!)反向后行断言,指定在主表达式之前无法匹配的组,如果匹配,则结果将被丢弃
可以翻译为:(?<!表达式)左边不存在
 微信
微信 支付宝
支付宝